【学習記録】PythonでKaggleのTitanicを解いた
活動内容
機械学習の可視化~予測までの一連の流れを演習し、現状を確認する目的でKaggleに登録しタイタニックの死亡者予測問題を解いてみた。
簡単な前処理を行い、モデルはランダムフォレストを選択した。予測精度は79.4%を記録。
可視化やモデルの学習を通し統計や数学の理論に対する理解の不足を痛感。
ロジスティック回帰程度であれば式の意味まで理解できるが、他は概要だけ知っていたり、完全なブラックボックスとなっていたりまちまち。
再現性のない80.3%の精度だしてよろこんでたりと色々あれ。
またそれを実装する手段としてのライブラリの知識にも欠けていた。
ぶっちゃけ分析してた時はdescribe()とcorr()しか打ってない。終わった後コピペして持ってきた。seabornとか分からん。
今後、Kaggleに有志がUpした模範解答を用いて、自身の現状と照らし合わせ、差異を学習する予定。
一回意味理解しながら模範解答写経する。
自然言語処理や音楽に興味があるので、いずれ手を出していきたい。(出来れば)
コード
色々ひどすぎるが自戒を込めて残しておく。
後からコメント書いたりとか面倒くさいので最初からしっかりコメントは残すこと。
やっぱ業務でエクセルとパワポしか使ってないやつは駄目だわ。転職しょ……
本作業の目的:データ可視化~予測まで機会学習プロセスの一連の流れを学ぶ。(機械学習のプログラミング設計は対象外)
目次:
1.データの可視化
1-1.データの読み込みと欠損値の確認
1-2.一先ずの可視化
1-3.欠損値を埋める(仮)
1-4.可視化と仮説
2.分析設計(何となく)
3.前処理
3-1.トレーニングデータ前処理
3-2.テストデータ前処理
4.学習
4-1.トレーニングデータ分割
4-2.モデル生成、学習、検証(PoC)
4-3.ハイパーパラメーターチューニング(RandomForest),検証
5.予測
5-1.予測
5-2.CSV出力
1-1.データの読み込みと欠損値の確認
・データの読み込み
#データ読み込み import pandas as pd df_train = pd.read_csv("train.csv") #トレーニングデータの読み込み df_train.head(3) #最初の3行だけ表示
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
データが読み込めた。各列の説明は公式資料を参照。
・欠損値の確認
#欠損値確認 print(df_train.shape) #行列確認 print(df_train.isnull().sum()) #欠損値確認
(891, 12)
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
全891行のデータの中で、少なくともAgeが欠損しているのが177行、少なくともCabinが欠損しているのが687行、Embarkedは2行
これらのデータについて欠損値を埋めてあげる必要がある。
・欠損値穴埋めの方針策定
Ageは年齢データなので一先ず平均か中央値で埋める。状況次第で予測モデルによる穴埋めを考慮する。
Cabinは687/891の欠損率であり、学習には一先ず使用しない事を考慮する。ゼロで穴埋めし前処理時点で列を削除する。
Embarkedは2件のみ欠損している質的変数であるので、最も出現する値で埋める。予定
いずれにせよ、可視化を行ってから判断する。
1-2.一先ずの可視化
#データ確認
df_train.describe()
| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| count | 891.000000 | 891.000000 | 891.000000 | 714.000000 | 891.000000 | 891.000000 | 891.000000 |
| mean | 446.000000 | 0.383838 | 2.308642 | 29.699118 | 0.523008 | 0.381594 | 32.204208 |
| std | 257.353842 | 0.486592 | 0.836071 | 14.526497 | 1.102743 | 0.806057 | 49.693429 |
| min | 1.000000 | 0.000000 | 1.000000 | 0.420000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 223.500000 | 0.000000 | 2.000000 | 20.125000 | 0.000000 | 0.000000 | 7.910400 |
| 50% | 446.000000 | 0.000000 | 3.000000 | 28.000000 | 0.000000 | 0.000000 | 14.454200 |
| 75% | 668.500000 | 1.000000 | 3.000000 | 38.000000 | 1.000000 | 0.000000 | 31.000000 |
| max | 891.000000 | 1.000000 | 3.000000 | 80.000000 | 8.000000 | 6.000000 | 512.329200 |
#相関確認
df_train.corr()
| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| PassengerId | 1.000000 | -0.005007 | -0.035144 | 0.036847 | -0.057527 | -0.001652 | 0.012658 |
| Survived | -0.005007 | 1.000000 | -0.338481 | -0.077221 | -0.035322 | 0.081629 | 0.257307 |
| Pclass | -0.035144 | -0.338481 | 1.000000 | -0.369226 | 0.083081 | 0.018443 | -0.549500 |
| Age | 0.036847 | -0.077221 | -0.369226 | 1.000000 | -0.308247 | -0.189119 | 0.096067 |
| SibSp | -0.057527 | -0.035322 | 0.083081 | -0.308247 | 1.000000 | 0.414838 | 0.159651 |
| Parch | -0.001652 | 0.081629 | 0.018443 | -0.189119 | 0.414838 | 1.000000 | 0.216225 |
| Fare | 0.012658 | 0.257307 | -0.549500 | 0.096067 | 0.159651 | 0.216225 | 1.000000 |
1-3.欠損値穴埋め作業
年齢確認
#年齢確認 import seaborn as sns import matplotlib.pyplot as plt g_age = sns.FacetGrid(data=df_train, col='Survived') g_age.map(plt.hist, 'Age', bins=20)
<seaborn.axisgrid.FacetGrid at 0x1fce688f978>
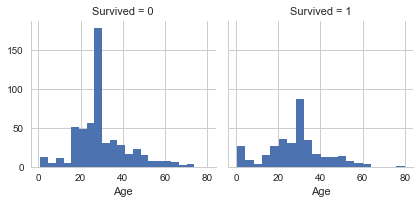
平均値で埋める予定。だめなら予測する。
Embarked確認
#Embarked確認 import matplotlib.pyplot as plt sns.countplot('Embarked',hue='Survived', data=df_train) vc_f = df_train['Embarked'].value_counts(sort=False) print(vc_f)
Q 77
S 644
C 168
Name: Embarked, dtype: int64
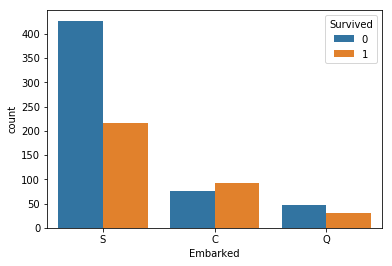
2件だけだし何で埋めても良さそう。此方もだめなら予測を使う。割合が違う。
Cabin確認
#Embarked確認 df_cabin=df_train[['Survived','Cabin','Fare']] df_cabin=df_cabin.dropna() df_cabin=df_cabin.replace('(,*)A(.*)','A', regex=True) #ループ処理とは一体…… df_cabin=df_cabin.replace('(,*)B(.*)','B', regex=True) df_cabin=df_cabin.replace('(,*)C(.*)','C', regex=True) df_cabin=df_cabin.replace('(,*)D(.*)','D', regex=True) df_cabin=df_cabin.replace('(,*)E(.*)','E', regex=True) df_cabin=df_cabin.replace('(,*)F(.*)','F', regex=True) df_cabin=df_cabin.replace('(,*)G(.*)','G', regex=True) pd.set_option("display.max_rows", 300) # df_cabin.head(500) # import seaborn as sns # import matplotlib.pyplot as plt # sns.countplot('Cabin',data=df_cabin) sns.countplot('Cabin',hue='Survived', data=df_cabin) # sns.countplot('Cabin',hue='Fare', data=df_cabin)
<matplotlib.axes._subplots.AxesSubplot at 0x1fce6243ba8>
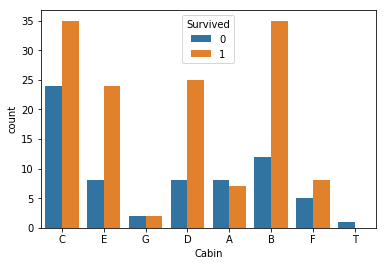
正規表現使ってCabinの頭文字を取得
なんか関係あるにはありそう。
そもそもこれ生きたやつの船室わかりやすいとかそういうケースじゃ……。
今回は面倒くさいので全部0にしてから列ごと消す。
1-4.可視化と仮説
・欠損値埋めて、ダミー変数化した上で可視化(このあたりのコードは後で前処理を行う際に恐らく使う)
#df_train_visualizeに可視化を行う。 #欠損値埋め、Age平均値,Cabin 0,Embarked S df_train_visualize=df_train.fillna({'Age':df_train['Age'].mean()}) df_train_visualize=df_train_visualize.fillna({'Cabin':0}) df_train_visualize=df_train_visualize.fillna({'Embarked':'S'}) #性別をダミー変数化して追加 sex_dum = pd.get_dummies(df_train_visualize['Sex']) df_train_visualize = pd.concat((df_train_visualize,sex_dum),axis=1) df_train_visualize = df_train_visualize.drop('Sex',axis=1) df_train_visualize = df_train_visualize.drop('female',axis=1) #Embarkedをダミー変数化して追加 emb_dum = pd.get_dummies(df_train_visualize['Embarked']) df_train_visualize = pd.concat((df_train_visualize,emb_dum),axis=1) df_train_visualize = df_train_visualize.drop('Embarked',axis=1) df_train__visualize = df_train_visualize.drop('S',axis=1) df_train_visualize.head(2)
| PassengerId | Survived | Pclass | Name | Age | SibSp | Parch | Ticket | Fare | Cabin | male | C | Q | S | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | 0 | 1 | 0 | 0 | 1 |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | 0 | 1 | 0 | 0 |
#使わないデータを除外し傾向確認 df_train_visualize_dn = df_train_visualize.dropna() df_train_visualize_dn = df_train_visualize_dn.drop('PassengerId',axis=1) df_train_visualize_dn = df_train_visualize_dn.drop('Name',axis=1) df_train_visualize_dn = df_train_visualize_dn.drop('Ticket',axis=1) df_train_visualize_dn = df_train_visualize_dn.drop('Cabin',axis=1)
・傾向確認
df_train_visualize_dn.corr()
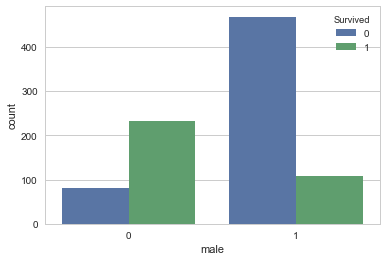
#性別が一番相関しており、次が年齢、基本的にこの順番で列を並べ替える。
| Survived | Pclass | Age | SibSp | Parch | Fare | male | C | Q | S | |
|---|---|---|---|---|---|---|---|---|---|---|
| Survived | 1.000000 | -0.338481 | -0.069809 | -0.035322 | 0.081629 | 0.257307 | -0.543351 | 0.168240 | 0.003650 | -0.149683 |
| Pclass | -0.338481 | 1.000000 | -0.331339 | 0.083081 | 0.018443 | -0.549500 | 0.131900 | -0.243292 | 0.221009 | 0.074053 |
| Age | -0.069809 | -0.331339 | 1.000000 | -0.232625 | -0.179191 | 0.091566 | 0.084153 | 0.032024 | -0.013855 | -0.019336 |
| SibSp | -0.035322 | 0.083081 | -0.232625 | 1.000000 | 0.414838 | 0.159651 | -0.114631 | -0.059528 | -0.026354 | 0.068734 |
| Parch | 0.081629 | 0.018443 | -0.179191 | 0.414838 | 1.000000 | 0.216225 | -0.245489 | -0.011069 | -0.081228 | 0.060814 |
| Fare | 0.257307 | -0.549500 | 0.091566 | 0.159651 | 0.216225 | 1.000000 | -0.182333 | 0.269335 | -0.117216 | -0.162184 |
| male | -0.543351 | 0.131900 | 0.084153 | -0.114631 | -0.245489 | -0.182333 | 1.000000 | -0.082853 | -0.074115 | 0.119224 |
| C | 0.168240 | -0.243292 | 0.032024 | -0.059528 | -0.011069 | 0.269335 | -0.082853 | 1.000000 | -0.148258 | -0.782742 |
| Q | 0.003650 | 0.221009 | -0.013855 | -0.026354 | -0.081228 | -0.117216 | -0.074115 | -0.148258 | 1.000000 | -0.499421 |
| S | -0.149683 | 0.074053 | -0.019336 | 0.068734 | 0.060814 | -0.162184 | 0.119224 | -0.782742 | -0.499421 | 1.000000 |
df_train_visualize_dn.head(2)
| Survived | Pclass | Age | SibSp | Parch | Fare | male | C | Q | S | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | 22.0 | 1 | 0 | 7.2500 | 1 | 0 | 0 | 1 |
| 1 | 1 | 1 | 38.0 | 1 | 0 | 71.2833 | 0 | 1 | 0 | 0 |
sns.set(style='whitegrid', context='notebook') cols = ['Survived','Age', 'Fare'] sns.pairplot(df_train_visualize_dn[cols], size=2.5) plt.show() #質的変数をダミー化したのが多いので参考にならない。
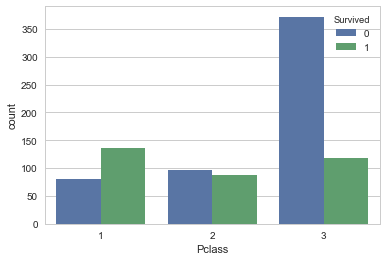
sns.countplot('Pclass',hue='Survived', data=df_train_visualize_dn)
<matplotlib.axes._subplots.AxesSubplot at 0x1fce671f198>
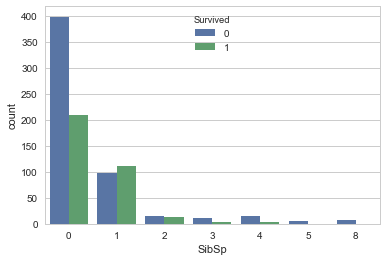
sns.countplot('SibSp',hue='Survived', data=df_train_visualize_dn)
<matplotlib.axes._subplots.AxesSubplot at 0x1fce68ee0f0>
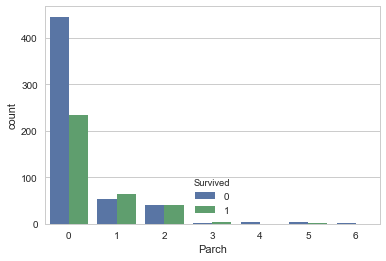
sns.countplot('Parch',hue='Survived', data=df_train_visualize_dn)
<matplotlib.axes._subplots.AxesSubplot at 0x1fce68eea90>
sns.countplot('male',hue='Survived', data=df_train_visualize_dn)
<matplotlib.axes._subplots.AxesSubplot at 0x1fce65c6400>
sns.countplot('C',hue='Survived', data=df_train_visualize_dn)
<matplotlib.axes._subplots.AxesSubplot at 0x1fce65bd9e8>
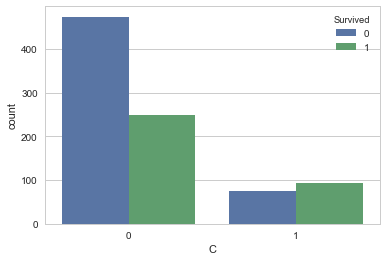
sns.countplot('Q',hue='Survived', data=df_train_visualize_dn)
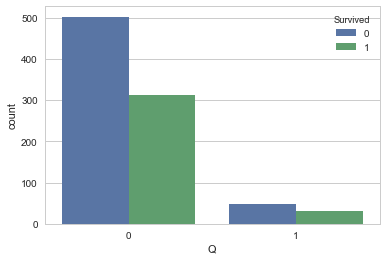
<matplotlib.axes._subplots.AxesSubplot at 0x1fce6727b00>
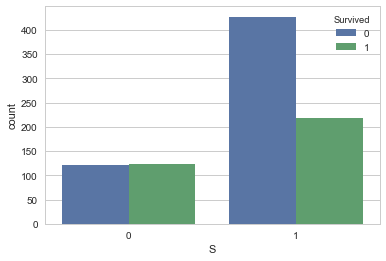
sns.countplot('S',hue='Survived', data=df_train_visualize_dn)
<matplotlib.axes._subplots.AxesSubplot at 0x1fce676c710>
2.分析設計
データ全部ぶち込んで適当にグリッドサーチする感じで……(説明放棄)
3.前処理
3-1.トレーニングデータ前処理
可視化した際のコードを再利用しつつ前処理
#欠損値埋め、Age平均値 df_train=df_train.fillna({'Age':df_train['Age'].mean()}) df_train=df_train.fillna({'Cabin':0}) df_train=df_train.fillna({'Embarked':'S'})
# df_train.head(100) #性別、乗船場所のダミー変数化 sex_dum = pd.get_dummies(df_train['Sex']) df_train_proc = pd.concat((df_train,sex_dum),axis=1) df_train_proc = df_train_proc.drop('Sex',axis=1) df_train_proc = df_train_proc.drop('female',axis=1) emb_dum = pd.get_dummies(df_train['Embarked']) df_train_proc = pd.concat((df_train_proc,emb_dum),axis=1) df_train_proc = df_train_proc.drop('Embarked',axis=1) df_train_proc = df_train_proc.drop('S',axis=1)
#使わないデータを除外 df_train_proc_dn = df_train_proc df_train_proc_dn = df_train_proc_dn.drop('PassengerId',axis=1) df_train_proc_dn = df_train_proc_dn.drop('Name',axis=1) df_train_proc_dn = df_train_proc_dn.drop('Ticket',axis=1) df_train_proc_dn = df_train_proc_dn.drop('Cabin',axis=1)
#検証用データ生成 target_train_pri=df_train_proc_dn.iloc[:,0].values data_train_pri = df_train_proc_dn.iloc[:,[6,1,5,2,3,4,7,8]].values
3-2.テストデータ前処理
可視化した際のコードを再利用しつつ前処理
#データ読み込み import pandas as pd df_test = pd.read_csv("test.csv") df_test.tail(2)
| PassengerId | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 416 | 1308 | 3 | Ware, Mr. Frederick | male | NaN | 0 | 0 | 359309 | 8.0500 | NaN | S |
| 417 | 1309 | 3 | Peter, Master. Michael J | male | NaN | 1 | 1 | 2668 | 22.3583 | NaN | C |
#欠損値確認 print(df_test.shape) #行列確認 print(df_test.isnull().sum()) #欠損値確認
(418, 11)
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 86
SibSp 0
Parch 0
Ticket 0
Fare 1
Cabin 327
Embarked 0
dtype: int64
#ダミー変数置き換え&不要列削除 sex_dum = pd.get_dummies(df_test['Sex']) df_test_proc = pd.concat((df_test,sex_dum),axis=1) df_test_proc = df_test_proc.drop('Sex',axis=1) df_test_proc = df_test_proc.drop('female',axis=1) emb_dum = pd.get_dummies(df_test['Embarked']) df_test_proc = pd.concat((df_test_proc,emb_dum),axis=1) df_test_proc = df_test_proc.drop('Embarked',axis=1) df_test_proc = df_test_proc.drop('S',axis=1) df_test_proc_dn = df_test_proc.drop('Cabin',axis=1) df_train_proc_dn = df_train_proc.dropna() df_test_proc_dn = df_test_proc_dn.drop('PassengerId',axis=1) df_test_proc_dn = df_test_proc_dn.drop('Name',axis=1) df_test_proc_dn = df_test_proc_dn.drop('Ticket',axis=1) #欠損値穴埋め df_test_proc_dn=df_test_proc_dn.fillna({'Age':df_test_proc_dn['Age'].mean()}) df_test_proc_dn=df_test_proc_dn.fillna({'Fare':df_test_proc_dn['Fare'].mean()}) df_test_proc_dn.tail(5)
| Pclass | Age | SibSp | Parch | Fare | male | C | Q | |
|---|---|---|---|---|---|---|---|---|
| 413 | 3 | 30.27259 | 0 | 0 | 8.0500 | 1 | 0 | 0 |
| 414 | 1 | 39.00000 | 0 | 0 | 108.9000 | 0 | 1 | 0 |
| 415 | 3 | 38.50000 | 0 | 0 | 7.2500 | 1 | 0 | 0 |
| 416 | 3 | 30.27259 | 0 | 0 | 8.0500 | 1 | 0 | 0 |
| 417 | 3 | 30.27259 | 1 | 1 | 22.3583 | 1 | 1 | 0 |
#列を整理しテストデータ作成 test_data=df_test_proc_dn.iloc[:,[5,0,4,1,2,3,6,7]].values
4.学習
4-1.トレーニングデータ分割
#データ分割 from sklearn import cross_validation data_train ,data_valid ,target_train, target_valid = cross_validation.train_test_split(data_train_pri , target_train_pri, test_size=0.2, random_state=0)
4-2.モデル生成、学習、検証(PoC)
・決定木
#決定木分析 from sklearn import tree tree_clf = tree.DecisionTreeClassifier(max_depth=3,min_samples_split = 10) tree_clf = tree_clf.fit(data_train, target_train) tree_predicted = tree_clf.predict(data_train) tree_predicted_valid=tree_clf.predict(data_valid)
#学習結果検証 print("未学習検証:訓練データ予測") print(sum(tree_predicted == target_train) / len(target_train)) print() print("過学習検証;検証データ予測") print(sum(tree_predicted_valid == target_valid) / len(target_valid))
未学習検証:訓練データ予測
0.834269662921
過学習検証;検証データ予測
0.821229050279
・ロジスティック回帰
#ロジスティック回帰 from sklearn import linear_model logi_clf = linear_model.LogisticRegression(C=0.1, max_iter=1000 ,penalty='l2') logi_clf.fit(data_train, target_train) logi_predicted = logi_clf.predict(data_train) logi_predicted_valid= logi_clf.predict(data_valid)
#学習結果検証 print("未学習検証:訓練データ予測") print(sum(logi_predicted == target_train) / len(target_train)) print() print("過学習検証;検証データ予測") print(sum(logi_predicted_valid == target_valid) / len(target_valid))
未学習検証:訓練データ予測
0.804775280899
過学習検証;検証データ予測
0.782122905028
・SVC with Grid_serach
from sklearn import svm from sklearn import grid_search parameters = { 'kernel': ['rbf'], 'gamma' : [0.003,0.0025,0.002], 'C' : [30,50,70,90,100], 'class_weight' :['balanced'], 'random_state' :[0] } svc_clf_grid = grid_search.GridSearchCV(svm.SVC() ,parameters, cv=10 ) svc_clf_grid.fit(data_train, target_train) print(svc_clf_grid.best_params_) print(svc_clf_grid.best_estimator_)
{'C': 90, 'class_weight': 'balanced', 'gamma': 0.002, 'kernel': 'rbf', 'random_state': 0}
SVC(C=90, cache_size=200, class_weight='balanced', coef0=0.0,
decision_function_shape='ovr', degree=3, gamma=0.002, kernel='rbf',
max_iter=-1, probability=False, random_state=0, shrinking=True,
tol=0.001, verbose=False)
svc_grid_predicted = svc_clf_grid.predict(data_train) svc_grid_predicted_valid= svc_clf_grid.predict(data_valid) #学習結果検証 print("未学習検証:訓練データ予測") print(sum(svc_grid_predicted == target_train) / len(target_train)) print() print("過学習検証;検証データ予測") print(sum(svc_grid_predicted_valid == target_valid) / len(target_valid))
未学習検証:訓練データ予測
0.851123595506
過学習検証;検証データ予測
0.815642458101
K近傍法(原理とパラメータの意味理解してないので参考程度)
from sklearn import neighbors n_neighbors = 3 K_clf=neighbors.KNeighborsClassifier(n_neighbors, weights = 'distance') K_clf.fit(data_train, target_train) K_predicted = K_clf.predict(data_train) K_predicted_valid= K_clf.predict(data_valid)
#学習結果検証 print("未学習検証:訓練データ予測") print(sum(K_predicted == target_train) / len(target_train)) print() print("過学習検証;検証データ予測") print(sum(K_predicted_valid == target_valid) / len(target_valid))
未学習検証:訓練データ予測
0.981741573034
過学習検証;検証データ予測
0.715083798883
4-3.ハイパーパラメーターチューニング(RandomForest),検証
#gridserach from sklearn import ensemble from sklearn import grid_search parameters = { 'n_estimators' : [5000], 'random_state' : [0], 'n_jobs' : [4], 'min_samples_split':[10,11,12,13,14,15], 'max_depth' : [5] } ranfore_clf_grid = grid_search.GridSearchCV(ensemble.RandomForestClassifier() ,parameters, cv=3) ranfore_clf_grid.fit(data_train,target_train)
GridSearchCV(cv=3, error_score='raise',
estimator=RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=1,
oob_score=False, random_state=None, verbose=0,
warm_start=False),
fit_params={}, iid=True, n_jobs=1,
param_grid={'n_estimators': [5000], 'random_state': [0], 'n_jobs': [4], 'min_samples_split': [10, 11, 12, 13, 14, 15], 'max_depth': [5]},
pre_dispatch='2*n_jobs', refit=True, scoring=None, verbose=0)
print(ranfore_clf_grid.best_estimator_)
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=5, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=13,
min_weight_fraction_leaf=0.0, n_estimators=5000, n_jobs=4,
oob_score=False, random_state=0, verbose=0, warm_start=False)
ranfore_predicted = ranfore_clf_grid.predict(data_train) ranfore_predicted_valid= ranfore_clf_grid.predict(data_valid) #学習結果検証 print("未学習検証:訓練データ予測") print(sum(ranfore_predicted == target_train) / len(target_train)) print() print("過学習検証;検証データ予測") print(sum(ranfore_predicted_valid == target_valid) / len(target_valid))
未学習検証:訓練データ予測
0.851123595506
過学習検証;検証データ予測
0.832402234637
from sklearn import ensemble from sklearn import grid_search ranfore_clf = ensemble.RandomForestClassifier(n_estimators=50000,max_depth=5, min_samples_split=15) ranfore_clf.fit(data_train, target_train) ranfore_predicted = ranfore_clf.predict(data_train) ranfore_predicted_valid= ranfore_clf.predict(data_valid) #学習結果検証 print("未学習検証:訓練データ予測") print(sum(ranfore_predicted == target_train) / len(target_train)) print() print("過学習検証;検証データ予測") print(sum(ranfore_predicted_valid == target_valid) / len(target_valid)) # 79.4%
未学習検証:訓練データ予測
0.852528089888
過学習検証;検証データ予測
0.837988826816
ranfore_clf2 = ensemble.RandomForestClassifier(n_estimators=50000,max_depth=5, min_samples_split=13) ranfore_clf2.fit(data_train, target_train) ranfore_predicted2 = ranfore_clf2.predict(data_train) ranfore_predicted_valid2= ranfore_clf2.predict(data_valid) #学習結果検証 print("未学習検証:訓練データ予測") print(sum(ranfore_predicted2 == target_train) / len(target_train)) print() print("過学習検証;検証データ予測") print(sum(ranfore_predicted_valid2 == target_valid) / len(target_valid))
未学習検証:訓練データ予測
0.851123595506
過学習検証;検証データ予測
0.837988826816
test_predicted = ranfore_clf6.predict(test_data) test_predicted_frame=pd.DataFrame(test_predicted) df_predicted = pd.concat((df_test.iloc[:,0],test_predicted_frame),axis=1) df_predicted.columns=['PassengerId', 'Survived'] df_predicted.head(10)
| PassengerId | Survived | |
|---|---|---|
| 0 | 892 | 0 |
| 1 | 893 | 0 |
| 2 | 894 | 0 |
| 3 | 895 | 0 |
| 4 | 896 | 1 |
| 5 | 897 | 0 |
| 6 | 898 | 1 |
| 7 | 899 | 0 |
| 8 | 900 | 1 |
| 9 | 901 | 0 |
df_predicted.to_csv('submission_forest8.csv',index=False)