AWS Elastic Beanstalkを使用したDjangoアプリケーションのデプロイとジョブの自動実行
1. 概要
AWS Elastic Beanstalkを使用してDjangoで知人が作成したアプリケーションをデプロイした。
開発環境がUnix系なのにWindowsで作業してるなど素人感満載だが、一応出来たので手順を残しておく。
2. 環境・前提
2.1 端末環境
・以下の環境で作業を実施
Windows 10 64bit Brackets 1.13 Python 3.6.6 Anaconda 1.6.13 (conda 4.5.4) Django 2.0.7
2.2 AWS
・EC2アクセス用のキーペアを作成済み
・AWS Elastic Beanstalk用のIAMユーザーを作成済み
2.3 Django
・superユーザー作成済み
・collectstatic,migrateは実施済み
・DBとして用意したSQlite3をそのまま継続使用
3. 手順
3-1. ElasticBeanstalkコマンドラインツールの導入
$ pip install awsebcli --upgrade --user
3-2. Django projectにファイルを追加
::事前に構築済みの開発用環境を起動し、ElasticBeanstalk用にパッケージ情報を保存
$ conda activate (eb-virt)
(eb-virt)$ cd {アプリケーションのBASE_DIR}
(eb-virt)$ pip freeze > requirements.txt
::環境設定ファイル作成
(eb-virt)$ conda deactivate
$ mkdir .ebextensions
$ cd .ebextensions
$ type nul > django.config
$ Brackets django.config
django.configに以下を記載
option_settings:
"aws:elasticbeanstalk:application:environment":
DJANGO_SETTINGS_MODULE: "{アプリケーション名}.settings"
"PYTHONPATH": "/opt/python/current/app/:$PYTHONPATH"
"ALLOWED_HOSTS": ".elasticbeanstalk.com"
"aws:elasticbeanstalk:container:python":
WSGIPath: {アプリケーション名}/wsgi.py
NumProcesses: 3
NumThreads: 20
"aws:elasticbeanstalk:container:python:staticfiles":
"/static/": "static/"
3-3. デプロイまで
アプリケーションのBASE_DIR上で以下を実行
eb init -p python-3.6
いくつか設定項目(リージョンやアクセスキーなど)を聞かれるので回答する
リージョン
Select a default region 9) ap-northeast : Asia Pacific (Tokyo)
アクセスキーにはAWSElasticBeanstalkFullAccessのポリシーを割り当てたIAMを使用
You must provide your credentials. (aws-access-id): 発行したアクセスキー (aws-secret-key): シークレットキー
他、アプリ名やEC2に接続するキーペアを聞かれるので回答しておく。
Cannot setup CodeCommit because there is no Source Control setup, continuing with initialization Do you want to set up SSH for your instances? (Y/n):
以下のコマンドを実行すると自動で環境構築を実施してくれる。
$ eb create {環境名}
設定値は以下のコマンドで確認可能
エラー出たときとかに見る
$ eb config
デプロイ実施 以下のコマンドでデプロイ実施
$ eb deploy
3-4. Cron設定まで
python manage.py {コマンド}を15分間隔で実施したい。
.ebextension内にcronjob.configを作成、下記のように設定する
container_commands:
cron.exec_trade:
command: "cat .ebextensions/{クーロン名}.cron > /etc/cron.d/{クーロン名} && chmod 644 /etc/cron.d/{クーロン名}"
leader_only: true
remove_old_cron:
command: "rm -f /etc/cron.d/*.bak"
{クーロン名}.cronの中身は下記のように設定
SHELL=/bin/bash
PATH=/sbin:bin:/usr/sbin:/usr/bin
MAILTO=root
HOME=/
*/15 * * * * root source /opt/python/current/env && /opt/python/run/venv/bin/python3 /opt/python/current/app/manage.py {コマンド名} >> /var/log/cronjobs.log 2>> /var/log/cronjobs-err.log
※ここでWindows上でファイルを作ってしまったせいで改行コードが\r\nとなり、cronは\nじゃないと動かないので悲しみを背負う
ちゃんと開発環境で作業すべき
作業時はEC2上でodコマンド→trコマンドで原因の解明→解決となったが、最終的にSUSE上でファイルを1から作り直した
/var/log/cronや自分で設定したログの出力先見る感じ動いてて僕満足
Appendix1. ディレクトリ構造抜粋
{アプリケーション名}
├── db.sqlite3
├── .ebextensions
│ ├── cronjob.config
│ ├── django.config
│ ├── {クーロン名}.cron
├──.elasticbeanstalk
│ ├── config.yml
│ └─saved_configs
├── {アプリケーション名}
│ ├── settings.py
│ ├── wsgi.py
├── static
├── manage.py
└── requirements.txt
collectstaticやmigrateなどのコマンドも.ebextensions内のconfig内に設定することで勝手にやってくれるらしい。
今回はやらなかったが機会があればやる。
Appendix2. 参考にしたページなど
Elastic Beanstalk への Django アプリケーションのデプロイ - AWS Elastic Beanstalk
Elastic Beanstalk 環境で EC2インスタンスによる Cron ジョブの作成
Deploying a Django App to AWS Elastic Beanstalk – Real Python
Elastic Beanstalk + Python 3.6 + Django 2.0.5
[Elastic Beanstalk入門] Djangoアプリケーションのデプロイ その①|ハンズラボエンジニアブログ|ハンズラボ株式会社
【備忘録】2017年度に読んだ本まとめ
【概要】
2017年度に読んだ本の中で良かった本をメモしておく。
背景として私生活の話をすると、有機系の太陽電池の研究をしていた修士課程を終えて新卒でコンサルティングファームに就職。1年目を過ごした。
技術書を除き、読んだ本の中から個人的に上位30%くらいの書籍を対象に短く感想を残しておく。
【感想】
・白石 隆『海の帝国』(中公新書)
東南アジアの地域秩序の変遷についてマクロ的視点で描いた本。
仕事で東南アジアに飛ばされると完全に思い込んでた時期に形から入ろうと買った。
特に第二次大戦後の地域秩序については知識を持っていなかったので参考になった。
本筋から少々逸れるが、「近代的自我の目覚め」として引用されているジャワ人少女の描写が秀逸だった。
・猪木 武徳『戦後世界経済史―自由と平等の視点から』(中公新書)
第二次大戦後の世界史を経済の観点で纏めた本。やたら分厚い。
社会人になったので、経済的な本も読んでおこうと買った。
後進国同士の経済発展の差について分析している箇所はとても興味深かった。
政治の安定・自由と経済発展の関係などの観点で総括もされている。
・遠藤 周作『王の挽歌』(新潮文庫)
戦国大名の一人、大友宗麟が主人公の小説。
新人研修中のグループワーク()で精神を限界まですり減らした際に読んだ。
物語の雰囲気は終始暗い。主人公は精神的な苦悩を抱えているが、戦国大名として様々な問題に対処する責任がある。
そうした人物を親に持つ子にも苦悩があり、最終的に大友氏は宗麟の子の代で改易されてしまう。
大友宗麟と豊臣秀吉二人が千利休を交えて向かいあう場面は非常に印象的だった。
二人を通して、内面の苦悩と闘い続けた者とそのような苦悩を覚える事無く社会の回想を駆け上がった者とが対比される。
その中で主人公は秀吉の姿を見て苦悩し続けた自らの人生を誇り高く感じていた。
僕の好きな人物の類型に「常人とは比較にならぬ程強い精神的な苦悩を抱えながら、行動し続けた/する他なかった」という物があり、本作の宗麟もまたそういう人物だった。
・三谷 太一郎『日本の近代とは何であったか――問題史的考察 』(岩波新書)
日本の近代を①政党政治②資本主義③植民地化④天皇制の観点で分析する本。
明治憲法下の権力分散のメカニズムを、西洋的な視点ではなく、合議制が主であった幕藩体制の延長として捉える等、新鮮な視点が多かった。
教育勅語に含まれた意図と結果、そして弊害についても詳しく抱えており、参考になる。
やや思想の匂いを感じたものの日本の近代を捉え直すにはオススメの良書。
・ウィリアム・H・マクニール『疫病と世界史』(中公文庫)
疫病の観点から人類史を語る文句なしの名著。
同著者の『世界史』と『戦争の世界史』やジャレド・ダイヤモンド氏の著作や『サピエンス全史』などは既読で、そろそろ読もうと思って購入した。
論の展開が強引な箇所もあるが、歴史に残された証拠を元に背景を考察していくプロセスの数々は大変興味深い物だった。
特に疫病と信仰の関係について考察した箇所が印象的だった。
・マーク・マゾワー『バルカン―「ヨーロッパの火薬庫」の歴史』(中公新書)
バルカン半島の歴史について記載した本。
新刊チェック時に発見し即購入。サラエボ事件とチトーしか知らない人間だったが、セルビアオタクの友人にギリギリ追従できる知識がついた。
バルカン半島のような民族分布が複雑に入り組んだ地域を学ぶと民族自決の弊害を否が応でも知る事になる。
自分が密かに抱えている個人的なテーマの一つである「寛容性の獲得」について改めて意識する事が出来た。
・岡田 暁生『オペラの運命―十九世紀を魅了した「一夜の夢」』(中公新書)
オペラの歴史について解説した本。
著者買い。以前読んだ氏の著作『音楽の聴き方』ではベートーヴェンの第九に関わる一連の描写が素晴らしかった。
本著においてもその描写力が遺憾なく発揮されている。
また、オペラを単なる劇としてではなく観客も含めた「場」として捉える事や、国民的音楽に潜む二面性(同胞意識と国威発揚の相反性)などの解説は非常に興味深いものであった。
・亀田 敏和『観応の擾乱 - 室町幕府を二つに裂いた足利尊氏・直義兄弟の戦い』(中公新書)
観応の擾乱を扱った本。AD1300~1500の日本史は分からない(AD1400~の関東限定なら分かる)が、隠れ太平記ファンの一人なので発売日に書店に駆け込んだ。
非常に噛み砕いて解説してくれているのだが、如何せん元々の乱が意味不明レベルの難解さであり、理解は困難を極めた。
細かい乱の推移と各人物の所属陣営は殆ど頭に入ってこなかったが、人物や社会の分析などは刺激的だった。
筆者の洞察を通して、報酬を適切に分配する制度作りの難しさと、努力が報われる社会の重要性を再認識する事が出来た。
・近江 俊秀『古代日本の情報戦略』(朝日選書)
古代日本の情報通信技術と戦略、特に駅制について解説する本。
同期から借りた。中央集権国家だからこそ出来るスケールの大きな計画と成果物の一つである直線の街道。
さながら日本版のローマ街道に無邪気な高揚を感じたが、社会の変化とともに制度の維持が困難となり、崩壊に至るまでの経緯は物悲しさを感じさせるものだった。
「全ての伝統や制度は定期的にそれが当初の目的に対し合理的であるか再検討する必要がある」という自分の考えが悲哀と共に強化された。
・細谷 雄一『国際秩序 - 18世紀ヨーロッパから21世紀アジアへ』(中公新書)
高坂正堯の『国際政治』という名著があるが、この本では『国際政治』で主に取り上げられていた勢力均衡以外にも協調や共同体の概念を取り上げ、それらを独立・複合的に解説する中で多面的に平和・秩序について洞察している。
ウィーン体制やビスマルク体制を単なる勢力均衡の視点でしか捉えきれていなかったが、本書を読み安易なお花畑外交とは別種の協調の概念を理解できた。
『国際政治』と等しく外交の話をするなら各種の教科書とあわせ、最低限読むべき本に挙げたいと思う。
・君塚 直隆『ヴィクトリア女王―大英帝国の“戦う女王”』(中公新書)
本屋で見かけて買った本。イギリス史については別の本でそれなりに理解出来ていたので、話はすんなり入ってきた。
イギリスが世界最強だった時代。イギリスは清教徒革命終わった辺りから王より政治家の名前の方がフォーカスされる感覚だが、この君主は君臨も統治もする。
第一次世界大戦時のロシア、ドイツ、イギリスの君主が全員彼女の孫という悲劇性の高さをこの本で初めて知った。
・桃井 治郎『海賊の世界史 - 古代ギリシアから大航海時代、現代ソマリアまで』(中公新書)
世界各地の海賊について解説した本。
オスマン帝国が健在だった頃のモロッコやアルジェリア、リビアに海賊が跋扈していたというのを初めて知る。
バルバリア海賊はトルコ沿岸部から出撃してると勝手に思い込んでたが、北アフリカが本拠地だった。彼らによって繰り返される襲撃の影響で地中海の沿岸部の住人が激減したというのは驚きだった。
また、北アフリカの海賊国家がアメリカやヨーロッパ各国と外交を行っていたというのも興味深い記述だった。
ヨーロッパ対立の隙間で生きていた海賊たちが、ウィーン体制でヨーロッパに生まれた協調によって駆逐されていく顛末も含め、自分にとって未知だらけの本で非常に刺激となった。
・飯田 洋介『ビスマルク - ドイツ帝国を築いた政治外交術』(中公新書)
クレッチマーの『天才の心理学』に記されていた彼の性格上の両極性を意識しながら読んだ。
一般的な天才外交家のイメージは覆されたが、意図せざる結果に策士策に溺れる形になりながらも結果的に上手く納めてしまう天性の術に惚れる。
また、意外に保守的な人間で伝統社会を守ろうとしていた事に驚いた。
死後の神格化にも触れられていて、「戦艦ビスマルク」という名が当時のドイツでどのような意味を持っていたかも知ることが出来た。
まぁ沈んだんですけどね。ヒンデンブルグは爆発するし。
ビスマルクという人物に性格的な類似を感じる事もあって、共感的に読み進めたが、最後は憂鬱な気持ちになってしまった。
彼は幸せだったのだろうか。そんな考えが読後にふと浮かんで消える。
余談だがTwitterに読了報告したら著者にいいねされた。恥ずかしくて黙殺しましたが研究頑張ってください。陰ながら応援してます。(コミュ障)
・河合 秀和『チャーチル―イギリス現代史を転換させた一人の政治家』(中公新書)
ビスマルクからのチャーチル。少年期に年上の先輩(将来的に政治家になるはず)をプールに突き落としたりする面白エピソードあり。
自分を英雄と同一視していたり、ダメな部分も多いわ周囲から嫌われて不遇の時期を過ごしたりするのだが、不満吐き出していても終始楽しそうにしか見えないのは、彼の行動力故か。
バトル・オブ・ブリテンやら鉄のカーテンやら造語のセンスもあり、絵も趣味でプロレベル。
ビスマルクとは真逆の、だが同じく魅力的な人物で、読んでいて楽しい気分になった。
・石野 裕子『物語 フィンランドの歴史 - 北欧先進国「バルトの乙女」の800年』(中公新書)
独立の節目なので読む。リーナス・トーバルズの出身国でもあるため、エンジニア(自称)の端くれとしては無視できない国。
シモ・ヘイヘやマンネルヘイムを知ってる程度だったが、第二次大戦以前、以後のフィンランドについての概要を学ぶ事が出来た。
ソ連の圧力と戦い続け、最後は民族揺籃の地カレリアをソ連に奪われる望郷の悲劇的国家イメージを持っていたが、カレリアが揺籃の地にされるまでの流れや、継続戦争でノリノリでソ連に攻め込む記述(大フィンランド)を見て唖然。
だが、リュティとマンネルヘイムのナチスに対する外交などは僕の琴線に触れた。
・渡辺 正峰『脳の意識 機械の意識 - 脳神経科学の挑戦』(中公新書)
本の内容は想像以上に攻めていた。
前提無しでは突拍子も無い事なのに、現実の事例から検証可能性に立脚した論を展開していくので、寧ろ納得してしまう。筆者の能力に脱帽。
知的刺激としては2017年度最大のヒット。
・角山 栄『茶の世界史 改版 - 緑茶の文化と紅茶の世界』(中公新書)
思いつきで読む。明治期に日本茶の海外輸出やろうとして失敗した話があり、興味深かった。
何故、イギリスでは茶なのかについて、歴史を軸に語られていた。
・著者多数『失敗の本質―日本軍の組織論的研究』(中公文庫)
特別枠。読んだ本は時折パラパラめくって再読するが、2017年度では一からしっかり再読した唯一の本。
日本人必読レベルの名著だと思っている。
・渡辺 克義『物語 ポーランドの歴史 - 東欧の「大国」の苦難と再生』(中公新書)
映画『With Fire and Sword』を見てポーランド熱が燃えていた時に読んだ。
興味のあったのはポーランド・リトアニア共和国~分割のあたりだが、記載が少なく残念。
本書のメインはWW2。レジスタンスの現金輸送車襲撃や暗殺などは現場での各員の位置関係などが図示されていて分かりやすかった。
ポーランドと言えば、の303飛行中隊の話もある。
戦後についても知れたので良かった。
・吉田 裕『日本軍兵士―アジア・太平洋戦争の現実』(中公新書)
食料や医療が不足する劣悪な補給状態で、兵士一人一人が直面した凄惨な体験が描かれていた。労働集約的(生産性が低い)な組織構造や白兵主義など日本軍の代表的な欠点についても触れられている。
兵站は超重要だということを再認識した。
【総括】
社会人1年目という事もあり、2017年度はあまり本を読む事が出来なかった。
全体的に中公新書が多い1年だった。(岩波文庫で興味ある奴は学生時代に殆ど読んでしまっている)
本のジャンルとしてはまず技術書がかなり増え、哲学を読まなくなった。
文学・芸術関係の本も割合としてはかなり少なくなっている。
詳細は省くが以前ほど所謂教養に対する興味が減じたのが原因である。
2018年度においては読書時間を減らし、技術と各種のアウトプットにリソースを費やしていきたい。
(ゲームやサイクリングといった動的な趣味は継続予定)
【学習記録】PythonでKaggleのTitanicを解いた
活動内容
機械学習の可視化~予測までの一連の流れを演習し、現状を確認する目的でKaggleに登録しタイタニックの死亡者予測問題を解いてみた。
簡単な前処理を行い、モデルはランダムフォレストを選択した。予測精度は79.4%を記録。
可視化やモデルの学習を通し統計や数学の理論に対する理解の不足を痛感。
ロジスティック回帰程度であれば式の意味まで理解できるが、他は概要だけ知っていたり、完全なブラックボックスとなっていたりまちまち。
再現性のない80.3%の精度だしてよろこんでたりと色々あれ。
またそれを実装する手段としてのライブラリの知識にも欠けていた。
ぶっちゃけ分析してた時はdescribe()とcorr()しか打ってない。終わった後コピペして持ってきた。seabornとか分からん。
今後、Kaggleに有志がUpした模範解答を用いて、自身の現状と照らし合わせ、差異を学習する予定。
一回意味理解しながら模範解答写経する。
自然言語処理や音楽に興味があるので、いずれ手を出していきたい。(出来れば)
コード
色々ひどすぎるが自戒を込めて残しておく。
後からコメント書いたりとか面倒くさいので最初からしっかりコメントは残すこと。
やっぱ業務でエクセルとパワポしか使ってないやつは駄目だわ。転職しょ……
本作業の目的:データ可視化~予測まで機会学習プロセスの一連の流れを学ぶ。(機械学習のプログラミング設計は対象外)
目次:
1.データの可視化
1-1.データの読み込みと欠損値の確認
1-2.一先ずの可視化
1-3.欠損値を埋める(仮)
1-4.可視化と仮説
2.分析設計(何となく)
3.前処理
3-1.トレーニングデータ前処理
3-2.テストデータ前処理
4.学習
4-1.トレーニングデータ分割
4-2.モデル生成、学習、検証(PoC)
4-3.ハイパーパラメーターチューニング(RandomForest),検証
5.予測
5-1.予測
5-2.CSV出力
1-1.データの読み込みと欠損値の確認
・データの読み込み
#データ読み込み import pandas as pd df_train = pd.read_csv("train.csv") #トレーニングデータの読み込み df_train.head(3) #最初の3行だけ表示
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
データが読み込めた。各列の説明は公式資料を参照。
・欠損値の確認
#欠損値確認 print(df_train.shape) #行列確認 print(df_train.isnull().sum()) #欠損値確認
(891, 12)
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
全891行のデータの中で、少なくともAgeが欠損しているのが177行、少なくともCabinが欠損しているのが687行、Embarkedは2行
これらのデータについて欠損値を埋めてあげる必要がある。
・欠損値穴埋めの方針策定
Ageは年齢データなので一先ず平均か中央値で埋める。状況次第で予測モデルによる穴埋めを考慮する。
Cabinは687/891の欠損率であり、学習には一先ず使用しない事を考慮する。ゼロで穴埋めし前処理時点で列を削除する。
Embarkedは2件のみ欠損している質的変数であるので、最も出現する値で埋める。予定
いずれにせよ、可視化を行ってから判断する。
1-2.一先ずの可視化
#データ確認
df_train.describe()
| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| count | 891.000000 | 891.000000 | 891.000000 | 714.000000 | 891.000000 | 891.000000 | 891.000000 |
| mean | 446.000000 | 0.383838 | 2.308642 | 29.699118 | 0.523008 | 0.381594 | 32.204208 |
| std | 257.353842 | 0.486592 | 0.836071 | 14.526497 | 1.102743 | 0.806057 | 49.693429 |
| min | 1.000000 | 0.000000 | 1.000000 | 0.420000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 223.500000 | 0.000000 | 2.000000 | 20.125000 | 0.000000 | 0.000000 | 7.910400 |
| 50% | 446.000000 | 0.000000 | 3.000000 | 28.000000 | 0.000000 | 0.000000 | 14.454200 |
| 75% | 668.500000 | 1.000000 | 3.000000 | 38.000000 | 1.000000 | 0.000000 | 31.000000 |
| max | 891.000000 | 1.000000 | 3.000000 | 80.000000 | 8.000000 | 6.000000 | 512.329200 |
#相関確認
df_train.corr()
| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| PassengerId | 1.000000 | -0.005007 | -0.035144 | 0.036847 | -0.057527 | -0.001652 | 0.012658 |
| Survived | -0.005007 | 1.000000 | -0.338481 | -0.077221 | -0.035322 | 0.081629 | 0.257307 |
| Pclass | -0.035144 | -0.338481 | 1.000000 | -0.369226 | 0.083081 | 0.018443 | -0.549500 |
| Age | 0.036847 | -0.077221 | -0.369226 | 1.000000 | -0.308247 | -0.189119 | 0.096067 |
| SibSp | -0.057527 | -0.035322 | 0.083081 | -0.308247 | 1.000000 | 0.414838 | 0.159651 |
| Parch | -0.001652 | 0.081629 | 0.018443 | -0.189119 | 0.414838 | 1.000000 | 0.216225 |
| Fare | 0.012658 | 0.257307 | -0.549500 | 0.096067 | 0.159651 | 0.216225 | 1.000000 |
1-3.欠損値穴埋め作業
年齢確認
#年齢確認 import seaborn as sns import matplotlib.pyplot as plt g_age = sns.FacetGrid(data=df_train, col='Survived') g_age.map(plt.hist, 'Age', bins=20)
<seaborn.axisgrid.FacetGrid at 0x1fce688f978>
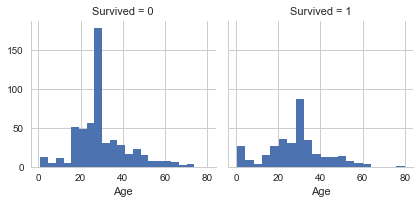
平均値で埋める予定。だめなら予測する。
Embarked確認
#Embarked確認 import matplotlib.pyplot as plt sns.countplot('Embarked',hue='Survived', data=df_train) vc_f = df_train['Embarked'].value_counts(sort=False) print(vc_f)
Q 77
S 644
C 168
Name: Embarked, dtype: int64
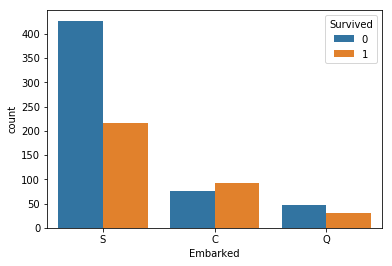
2件だけだし何で埋めても良さそう。此方もだめなら予測を使う。割合が違う。
Cabin確認
#Embarked確認 df_cabin=df_train[['Survived','Cabin','Fare']] df_cabin=df_cabin.dropna() df_cabin=df_cabin.replace('(,*)A(.*)','A', regex=True) #ループ処理とは一体…… df_cabin=df_cabin.replace('(,*)B(.*)','B', regex=True) df_cabin=df_cabin.replace('(,*)C(.*)','C', regex=True) df_cabin=df_cabin.replace('(,*)D(.*)','D', regex=True) df_cabin=df_cabin.replace('(,*)E(.*)','E', regex=True) df_cabin=df_cabin.replace('(,*)F(.*)','F', regex=True) df_cabin=df_cabin.replace('(,*)G(.*)','G', regex=True) pd.set_option("display.max_rows", 300) # df_cabin.head(500) # import seaborn as sns # import matplotlib.pyplot as plt # sns.countplot('Cabin',data=df_cabin) sns.countplot('Cabin',hue='Survived', data=df_cabin) # sns.countplot('Cabin',hue='Fare', data=df_cabin)
<matplotlib.axes._subplots.AxesSubplot at 0x1fce6243ba8>
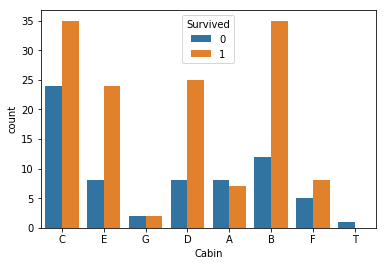
正規表現使ってCabinの頭文字を取得
なんか関係あるにはありそう。
そもそもこれ生きたやつの船室わかりやすいとかそういうケースじゃ……。
今回は面倒くさいので全部0にしてから列ごと消す。
1-4.可視化と仮説
・欠損値埋めて、ダミー変数化した上で可視化(このあたりのコードは後で前処理を行う際に恐らく使う)
#df_train_visualizeに可視化を行う。 #欠損値埋め、Age平均値,Cabin 0,Embarked S df_train_visualize=df_train.fillna({'Age':df_train['Age'].mean()}) df_train_visualize=df_train_visualize.fillna({'Cabin':0}) df_train_visualize=df_train_visualize.fillna({'Embarked':'S'}) #性別をダミー変数化して追加 sex_dum = pd.get_dummies(df_train_visualize['Sex']) df_train_visualize = pd.concat((df_train_visualize,sex_dum),axis=1) df_train_visualize = df_train_visualize.drop('Sex',axis=1) df_train_visualize = df_train_visualize.drop('female',axis=1) #Embarkedをダミー変数化して追加 emb_dum = pd.get_dummies(df_train_visualize['Embarked']) df_train_visualize = pd.concat((df_train_visualize,emb_dum),axis=1) df_train_visualize = df_train_visualize.drop('Embarked',axis=1) df_train__visualize = df_train_visualize.drop('S',axis=1) df_train_visualize.head(2)
| PassengerId | Survived | Pclass | Name | Age | SibSp | Parch | Ticket | Fare | Cabin | male | C | Q | S | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | 0 | 1 | 0 | 0 | 1 |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | 0 | 1 | 0 | 0 |
#使わないデータを除外し傾向確認 df_train_visualize_dn = df_train_visualize.dropna() df_train_visualize_dn = df_train_visualize_dn.drop('PassengerId',axis=1) df_train_visualize_dn = df_train_visualize_dn.drop('Name',axis=1) df_train_visualize_dn = df_train_visualize_dn.drop('Ticket',axis=1) df_train_visualize_dn = df_train_visualize_dn.drop('Cabin',axis=1)
・傾向確認
df_train_visualize_dn.corr()
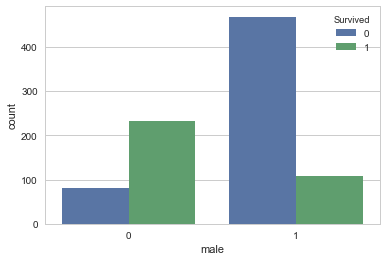
#性別が一番相関しており、次が年齢、基本的にこの順番で列を並べ替える。
| Survived | Pclass | Age | SibSp | Parch | Fare | male | C | Q | S | |
|---|---|---|---|---|---|---|---|---|---|---|
| Survived | 1.000000 | -0.338481 | -0.069809 | -0.035322 | 0.081629 | 0.257307 | -0.543351 | 0.168240 | 0.003650 | -0.149683 |
| Pclass | -0.338481 | 1.000000 | -0.331339 | 0.083081 | 0.018443 | -0.549500 | 0.131900 | -0.243292 | 0.221009 | 0.074053 |
| Age | -0.069809 | -0.331339 | 1.000000 | -0.232625 | -0.179191 | 0.091566 | 0.084153 | 0.032024 | -0.013855 | -0.019336 |
| SibSp | -0.035322 | 0.083081 | -0.232625 | 1.000000 | 0.414838 | 0.159651 | -0.114631 | -0.059528 | -0.026354 | 0.068734 |
| Parch | 0.081629 | 0.018443 | -0.179191 | 0.414838 | 1.000000 | 0.216225 | -0.245489 | -0.011069 | -0.081228 | 0.060814 |
| Fare | 0.257307 | -0.549500 | 0.091566 | 0.159651 | 0.216225 | 1.000000 | -0.182333 | 0.269335 | -0.117216 | -0.162184 |
| male | -0.543351 | 0.131900 | 0.084153 | -0.114631 | -0.245489 | -0.182333 | 1.000000 | -0.082853 | -0.074115 | 0.119224 |
| C | 0.168240 | -0.243292 | 0.032024 | -0.059528 | -0.011069 | 0.269335 | -0.082853 | 1.000000 | -0.148258 | -0.782742 |
| Q | 0.003650 | 0.221009 | -0.013855 | -0.026354 | -0.081228 | -0.117216 | -0.074115 | -0.148258 | 1.000000 | -0.499421 |
| S | -0.149683 | 0.074053 | -0.019336 | 0.068734 | 0.060814 | -0.162184 | 0.119224 | -0.782742 | -0.499421 | 1.000000 |
df_train_visualize_dn.head(2)
| Survived | Pclass | Age | SibSp | Parch | Fare | male | C | Q | S | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | 22.0 | 1 | 0 | 7.2500 | 1 | 0 | 0 | 1 |
| 1 | 1 | 1 | 38.0 | 1 | 0 | 71.2833 | 0 | 1 | 0 | 0 |
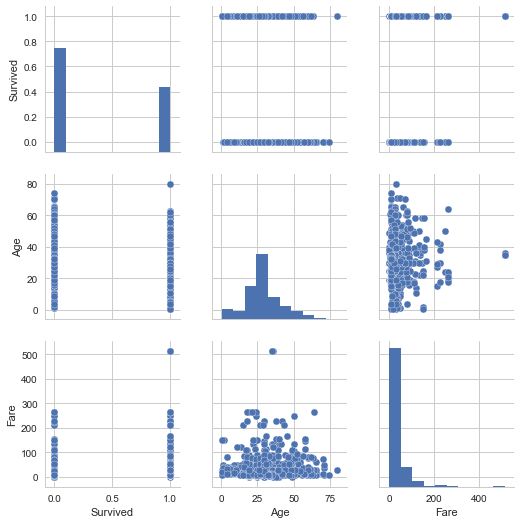
sns.set(style='whitegrid', context='notebook') cols = ['Survived','Age', 'Fare'] sns.pairplot(df_train_visualize_dn[cols], size=2.5) plt.show() #質的変数をダミー化したのが多いので参考にならない。
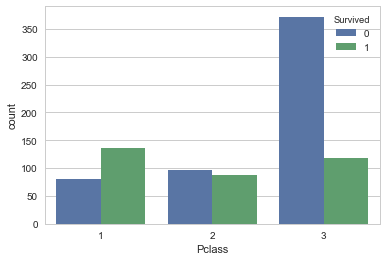
sns.countplot('Pclass',hue='Survived', data=df_train_visualize_dn)
<matplotlib.axes._subplots.AxesSubplot at 0x1fce671f198>
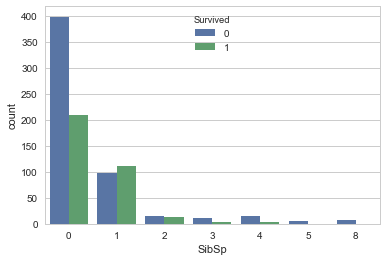
sns.countplot('SibSp',hue='Survived', data=df_train_visualize_dn)
<matplotlib.axes._subplots.AxesSubplot at 0x1fce68ee0f0>
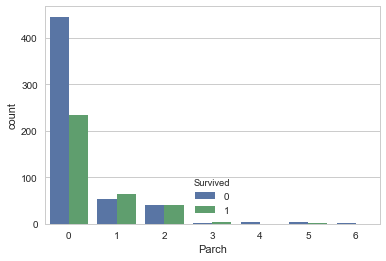
sns.countplot('Parch',hue='Survived', data=df_train_visualize_dn)
<matplotlib.axes._subplots.AxesSubplot at 0x1fce68eea90>
sns.countplot('male',hue='Survived', data=df_train_visualize_dn)
<matplotlib.axes._subplots.AxesSubplot at 0x1fce65c6400>
sns.countplot('C',hue='Survived', data=df_train_visualize_dn)
<matplotlib.axes._subplots.AxesSubplot at 0x1fce65bd9e8>
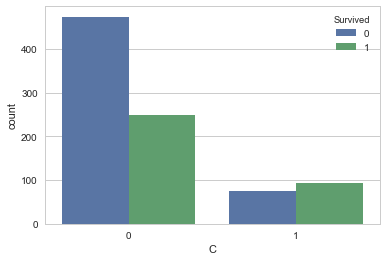
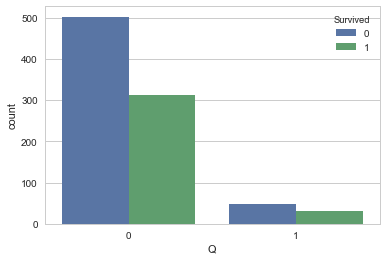
sns.countplot('Q',hue='Survived', data=df_train_visualize_dn)
<matplotlib.axes._subplots.AxesSubplot at 0x1fce6727b00>
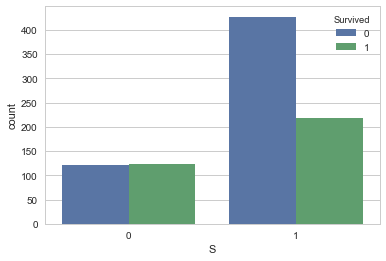
sns.countplot('S',hue='Survived', data=df_train_visualize_dn)
<matplotlib.axes._subplots.AxesSubplot at 0x1fce676c710>
2.分析設計
データ全部ぶち込んで適当にグリッドサーチする感じで……(説明放棄)
3.前処理
3-1.トレーニングデータ前処理
可視化した際のコードを再利用しつつ前処理
#欠損値埋め、Age平均値 df_train=df_train.fillna({'Age':df_train['Age'].mean()}) df_train=df_train.fillna({'Cabin':0}) df_train=df_train.fillna({'Embarked':'S'})
# df_train.head(100) #性別、乗船場所のダミー変数化 sex_dum = pd.get_dummies(df_train['Sex']) df_train_proc = pd.concat((df_train,sex_dum),axis=1) df_train_proc = df_train_proc.drop('Sex',axis=1) df_train_proc = df_train_proc.drop('female',axis=1) emb_dum = pd.get_dummies(df_train['Embarked']) df_train_proc = pd.concat((df_train_proc,emb_dum),axis=1) df_train_proc = df_train_proc.drop('Embarked',axis=1) df_train_proc = df_train_proc.drop('S',axis=1)
#使わないデータを除外 df_train_proc_dn = df_train_proc df_train_proc_dn = df_train_proc_dn.drop('PassengerId',axis=1) df_train_proc_dn = df_train_proc_dn.drop('Name',axis=1) df_train_proc_dn = df_train_proc_dn.drop('Ticket',axis=1) df_train_proc_dn = df_train_proc_dn.drop('Cabin',axis=1)
#検証用データ生成 target_train_pri=df_train_proc_dn.iloc[:,0].values data_train_pri = df_train_proc_dn.iloc[:,[6,1,5,2,3,4,7,8]].values
3-2.テストデータ前処理
可視化した際のコードを再利用しつつ前処理
#データ読み込み import pandas as pd df_test = pd.read_csv("test.csv") df_test.tail(2)
| PassengerId | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 416 | 1308 | 3 | Ware, Mr. Frederick | male | NaN | 0 | 0 | 359309 | 8.0500 | NaN | S |
| 417 | 1309 | 3 | Peter, Master. Michael J | male | NaN | 1 | 1 | 2668 | 22.3583 | NaN | C |
#欠損値確認 print(df_test.shape) #行列確認 print(df_test.isnull().sum()) #欠損値確認
(418, 11)
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 86
SibSp 0
Parch 0
Ticket 0
Fare 1
Cabin 327
Embarked 0
dtype: int64
#ダミー変数置き換え&不要列削除 sex_dum = pd.get_dummies(df_test['Sex']) df_test_proc = pd.concat((df_test,sex_dum),axis=1) df_test_proc = df_test_proc.drop('Sex',axis=1) df_test_proc = df_test_proc.drop('female',axis=1) emb_dum = pd.get_dummies(df_test['Embarked']) df_test_proc = pd.concat((df_test_proc,emb_dum),axis=1) df_test_proc = df_test_proc.drop('Embarked',axis=1) df_test_proc = df_test_proc.drop('S',axis=1) df_test_proc_dn = df_test_proc.drop('Cabin',axis=1) df_train_proc_dn = df_train_proc.dropna() df_test_proc_dn = df_test_proc_dn.drop('PassengerId',axis=1) df_test_proc_dn = df_test_proc_dn.drop('Name',axis=1) df_test_proc_dn = df_test_proc_dn.drop('Ticket',axis=1) #欠損値穴埋め df_test_proc_dn=df_test_proc_dn.fillna({'Age':df_test_proc_dn['Age'].mean()}) df_test_proc_dn=df_test_proc_dn.fillna({'Fare':df_test_proc_dn['Fare'].mean()}) df_test_proc_dn.tail(5)
| Pclass | Age | SibSp | Parch | Fare | male | C | Q | |
|---|---|---|---|---|---|---|---|---|
| 413 | 3 | 30.27259 | 0 | 0 | 8.0500 | 1 | 0 | 0 |
| 414 | 1 | 39.00000 | 0 | 0 | 108.9000 | 0 | 1 | 0 |
| 415 | 3 | 38.50000 | 0 | 0 | 7.2500 | 1 | 0 | 0 |
| 416 | 3 | 30.27259 | 0 | 0 | 8.0500 | 1 | 0 | 0 |
| 417 | 3 | 30.27259 | 1 | 1 | 22.3583 | 1 | 1 | 0 |
#列を整理しテストデータ作成 test_data=df_test_proc_dn.iloc[:,[5,0,4,1,2,3,6,7]].values
4.学習
4-1.トレーニングデータ分割
#データ分割 from sklearn import cross_validation data_train ,data_valid ,target_train, target_valid = cross_validation.train_test_split(data_train_pri , target_train_pri, test_size=0.2, random_state=0)
4-2.モデル生成、学習、検証(PoC)
・決定木
#決定木分析 from sklearn import tree tree_clf = tree.DecisionTreeClassifier(max_depth=3,min_samples_split = 10) tree_clf = tree_clf.fit(data_train, target_train) tree_predicted = tree_clf.predict(data_train) tree_predicted_valid=tree_clf.predict(data_valid)
#学習結果検証 print("未学習検証:訓練データ予測") print(sum(tree_predicted == target_train) / len(target_train)) print() print("過学習検証;検証データ予測") print(sum(tree_predicted_valid == target_valid) / len(target_valid))
未学習検証:訓練データ予測
0.834269662921
過学習検証;検証データ予測
0.821229050279
・ロジスティック回帰
#ロジスティック回帰 from sklearn import linear_model logi_clf = linear_model.LogisticRegression(C=0.1, max_iter=1000 ,penalty='l2') logi_clf.fit(data_train, target_train) logi_predicted = logi_clf.predict(data_train) logi_predicted_valid= logi_clf.predict(data_valid)
#学習結果検証 print("未学習検証:訓練データ予測") print(sum(logi_predicted == target_train) / len(target_train)) print() print("過学習検証;検証データ予測") print(sum(logi_predicted_valid == target_valid) / len(target_valid))
未学習検証:訓練データ予測
0.804775280899
過学習検証;検証データ予測
0.782122905028
・SVC with Grid_serach
from sklearn import svm from sklearn import grid_search parameters = { 'kernel': ['rbf'], 'gamma' : [0.003,0.0025,0.002], 'C' : [30,50,70,90,100], 'class_weight' :['balanced'], 'random_state' :[0] } svc_clf_grid = grid_search.GridSearchCV(svm.SVC() ,parameters, cv=10 ) svc_clf_grid.fit(data_train, target_train) print(svc_clf_grid.best_params_) print(svc_clf_grid.best_estimator_)
{'C': 90, 'class_weight': 'balanced', 'gamma': 0.002, 'kernel': 'rbf', 'random_state': 0}
SVC(C=90, cache_size=200, class_weight='balanced', coef0=0.0,
decision_function_shape='ovr', degree=3, gamma=0.002, kernel='rbf',
max_iter=-1, probability=False, random_state=0, shrinking=True,
tol=0.001, verbose=False)
svc_grid_predicted = svc_clf_grid.predict(data_train) svc_grid_predicted_valid= svc_clf_grid.predict(data_valid) #学習結果検証 print("未学習検証:訓練データ予測") print(sum(svc_grid_predicted == target_train) / len(target_train)) print() print("過学習検証;検証データ予測") print(sum(svc_grid_predicted_valid == target_valid) / len(target_valid))
未学習検証:訓練データ予測
0.851123595506
過学習検証;検証データ予測
0.815642458101
K近傍法(原理とパラメータの意味理解してないので参考程度)
from sklearn import neighbors n_neighbors = 3 K_clf=neighbors.KNeighborsClassifier(n_neighbors, weights = 'distance') K_clf.fit(data_train, target_train) K_predicted = K_clf.predict(data_train) K_predicted_valid= K_clf.predict(data_valid)
#学習結果検証 print("未学習検証:訓練データ予測") print(sum(K_predicted == target_train) / len(target_train)) print() print("過学習検証;検証データ予測") print(sum(K_predicted_valid == target_valid) / len(target_valid))
未学習検証:訓練データ予測
0.981741573034
過学習検証;検証データ予測
0.715083798883
4-3.ハイパーパラメーターチューニング(RandomForest),検証
#gridserach from sklearn import ensemble from sklearn import grid_search parameters = { 'n_estimators' : [5000], 'random_state' : [0], 'n_jobs' : [4], 'min_samples_split':[10,11,12,13,14,15], 'max_depth' : [5] } ranfore_clf_grid = grid_search.GridSearchCV(ensemble.RandomForestClassifier() ,parameters, cv=3) ranfore_clf_grid.fit(data_train,target_train)
GridSearchCV(cv=3, error_score='raise',
estimator=RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=1,
oob_score=False, random_state=None, verbose=0,
warm_start=False),
fit_params={}, iid=True, n_jobs=1,
param_grid={'n_estimators': [5000], 'random_state': [0], 'n_jobs': [4], 'min_samples_split': [10, 11, 12, 13, 14, 15], 'max_depth': [5]},
pre_dispatch='2*n_jobs', refit=True, scoring=None, verbose=0)
print(ranfore_clf_grid.best_estimator_)
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=5, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=13,
min_weight_fraction_leaf=0.0, n_estimators=5000, n_jobs=4,
oob_score=False, random_state=0, verbose=0, warm_start=False)
ranfore_predicted = ranfore_clf_grid.predict(data_train) ranfore_predicted_valid= ranfore_clf_grid.predict(data_valid) #学習結果検証 print("未学習検証:訓練データ予測") print(sum(ranfore_predicted == target_train) / len(target_train)) print() print("過学習検証;検証データ予測") print(sum(ranfore_predicted_valid == target_valid) / len(target_valid))
未学習検証:訓練データ予測
0.851123595506
過学習検証;検証データ予測
0.832402234637
from sklearn import ensemble from sklearn import grid_search ranfore_clf = ensemble.RandomForestClassifier(n_estimators=50000,max_depth=5, min_samples_split=15) ranfore_clf.fit(data_train, target_train) ranfore_predicted = ranfore_clf.predict(data_train) ranfore_predicted_valid= ranfore_clf.predict(data_valid) #学習結果検証 print("未学習検証:訓練データ予測") print(sum(ranfore_predicted == target_train) / len(target_train)) print() print("過学習検証;検証データ予測") print(sum(ranfore_predicted_valid == target_valid) / len(target_valid)) # 79.4%
未学習検証:訓練データ予測
0.852528089888
過学習検証;検証データ予測
0.837988826816
ranfore_clf2 = ensemble.RandomForestClassifier(n_estimators=50000,max_depth=5, min_samples_split=13) ranfore_clf2.fit(data_train, target_train) ranfore_predicted2 = ranfore_clf2.predict(data_train) ranfore_predicted_valid2= ranfore_clf2.predict(data_valid) #学習結果検証 print("未学習検証:訓練データ予測") print(sum(ranfore_predicted2 == target_train) / len(target_train)) print() print("過学習検証;検証データ予測") print(sum(ranfore_predicted_valid2 == target_valid) / len(target_valid))
未学習検証:訓練データ予測
0.851123595506
過学習検証;検証データ予測
0.837988826816
test_predicted = ranfore_clf6.predict(test_data) test_predicted_frame=pd.DataFrame(test_predicted) df_predicted = pd.concat((df_test.iloc[:,0],test_predicted_frame),axis=1) df_predicted.columns=['PassengerId', 'Survived'] df_predicted.head(10)
| PassengerId | Survived | |
|---|---|---|
| 0 | 892 | 0 |
| 1 | 893 | 0 |
| 2 | 894 | 0 |
| 3 | 895 | 0 |
| 4 | 896 | 1 |
| 5 | 897 | 0 |
| 6 | 898 | 1 |
| 7 | 899 | 0 |
| 8 | 900 | 1 |
| 9 | 901 | 0 |
df_predicted.to_csv('submission_forest8.csv',index=False)
Pythonを使ってWindowsSpotlight(ロック画面)の画像取得
【目的・背景】
①Windowsロック画面に表示される画像を保存してデスクトップ背景のスライドショーにしたかった。
②Microsoft StoreのアプリがPCで制限されている関係で、SpotBrightは使用不可、バッチファイルで画像取得まで完了済み
③コピーしてきたファイルには目的の解像度以外の画像データも含まれているため、これを削除したい。
【バッチファイル】
rem コピー元アドレスセット set copy_from=C:\Users\%USERNAME%\AppData\Local\Packages\Microsoft.Windows.ContentDeliveryManager_cw5n1h2txyewy\LocalState\Assets rem コピー先アドレスセット set copy_to=C:\Users\%USERNAME%\Desktop\Assets rem ディレクトリコピー echo D | xcopy %copy_from% %copy_to% /Y rem 怖いのでディレクトリ移動 cd C:\Users\%USERNAME%\Desktop\Assets rem ファイル名変更 ren * *.jpg
【Python】
PILを使用する。コードは次の通り
import os
import subprocess
import PIL.Image as img
#既成のバッチファイル呼び出し(画像取得)
os.system("kabegami.bat")
#ユーザーホーム取得
user = os.environ.get("USERPROFILE")
print(user)
#ファイルリスト取得
filelist =os.listdir(user+"/Desktop/Assets")
print(filelist)
os.chdir(user+"/Desktop/Assets")
#各ファイル毎の処理
#削除条件に合致したものを削除
for file in filelist:
try:
im = img.open(user+"/Desktop/Assets/"+file)
if im.size[0] == 1920:
im.close()
print("Pass")
else:#解像度が1920*でない物を削除
im.close()
print("Image_size_delete")
os.remove(user+"/Desktop/Assets/"+file)
except:#画像として認識できない物等を削除
print("exception_delete")
os.remove(user+"/Desktop/Assets/"+file)【運用】
①kabegami.batとspotlight.pyは同一ディレクトリに格納し、spotlight.pyを実行するだけ
Before(kabegami.batのみ)

After(spotlight.py実行)

やったぜ
【今後】
移動した後にもう一度バッチファイルを実行するなどして、既にある名称のファイルを持ってきた場合に問題が起こる。
ファイルのリネームが上手く行われず、拡張子がないファイルが残ってしまうのだ。
該当の拡張子がないファイルはimage.open()で開けてしまうので、今回作成したコードでは削除できない。
この問題へのアプローチとして「拡張子のないファイルを削除する」という条件を正規表現を使って追加しようと思ったが、30分程度で一旦挫折。
思えば、JavaJavaしてたときも正規表現は賢く使えていなかった。
今後の課題としてPythonで正規表現使った記法を一通りやってみたいと思う(やるとは言っていない)。
頭を使うのに疲れたのでエクセルとパワーポイントの自動翻訳に手を出した。
【背景・目的動機】
①海外のRFPとか要件定義書とか翻訳するのだるい。だるくない?そのまま読みゃいいだろ!
②ちょっとくらい、自動翻訳使ってもバレへんか……
【活動①】
Microsoftが出してるDocumentTranslatorを使用。
pronama.azurewebsites.net
Azureのアカウント必要なので使ってキー出す。


時代は機械翻訳。RNNの偉大さの前に跪け(素人並感)
【結果①】
お察し。
やっぱ自分で訳さねぇとダメだわ。
【活動②】
せめてエクセルで分類の翻訳だけは楽しようと英日対応表を作る。
機能要件・非機能要件あわせて大・中・小分類で300件程度。
貿易用語とか正直良く分からないがIT系の用語なら自信あります。取り敢えず横文字にすれば殆ど意味通じるし。

Sub RepRep()
Dim i As Long, Ws1 As Worksheet, Ws2 As Worksheet
Set Ws1 = Worksheets("Requirements")
Set Ws2 = Worksheets("英日対応(マクロ用)")
For i = 2 To Ws2.Cells(Rows.Count, "A").End(xlUp).Row
Ws1.Cells.Replace what:=Ws2.Cells(i, "A"), replacement:=Ws2.Cells(i, "B"), lookat:=xlWhole
Next i
End Sub
Requirementsシート内の各セルの値で英日対応表と完全一致するものを置換した。
【結果②】
いちいちCtrl+Fで置換する手間が省けたのでそれなりの時間削減にはなった。
要件の詳細などは普通に訳す必要があり大変面倒くさい。他のタスクもあったが、何とか終わらせた。(レビューでOKが出たとは言ってない)
もうこれ英語のままでよくね
WindowsSpotlight(ロック画面)の画像をデスクトップスライドショーにする。(SpotBright使えない時用)
【目的・背景】
①Windowsロック画面に表示される画像を保存してデスクトップ背景のスライドショーにしたかった。
②SpotBrightというアプリで実現しようとしたら拒否された。Microsoft Storeのアプリ全ブロックとか社用PCつらい。
③仕方がないのでローカルの保存先から引っ張る事にした。面倒なのでバッチファイル作った。
【バッチファイル】
rem コピー元アドレスセット set copy_from=C:\Users\%USERNAME%\AppData\Local\Packages\Microsoft.Windows.ContentDeliveryManager_cw5n1h2txyewy\LocalState\Assets rem コピー先アドレスセット set copy_to=C:\Users\%USERNAME%\Desktop\Assets rem ディレクトリコピー echo D | xcopy %copy_from% %copy_to% /Y rem 怖いのでディレクトリ移動 cd C:\Users\%USERNAME%\Desktop\Assets rem ファイル名変更 ren * *.jpg
【運用】
①テキストファイルにコピーして拡張子を.txtから.batに変えて実行(そこからか)
②Desktopに出来たAssetsフォルダ内に表示されたことのある画像が入ってるので、良さげな画像を手作業でスライドショー用のフォルダに移動。※1

※1画像のサムネイルはフォルダ上部のメニュータブから表示→オプション→表示→詳細設定で「常にアイコンを表示し、縮小版は表示しない」のチェックを外す。なんかいつの間にかサムネイル表示されなくなっててキレそう。
【今後】
ゴミファイルが含まれているので、自動削除したい。ファイルの解像度を取得し、指定の解像度で無いものを消す方法が考えられる。
コマンドプロンプト単体では不可能だと認識している。ちゃんとコード書くか、Imagemagick入れなきゃ無理っぽい。
CourseraのMachine Learningの受講を終えました。これから機械学習を始めたい方へのオススメと感想など
表題通りです。期間は10月中旬から11月下旬、だいたい40日くらいです。
講義は通常の予定ですと11Weekで修了なのですが、業後や休日に少し駆け足で進めました。
この講義ですが以下の方にオススメです。
・機械学習を初めから学んでみたい
・英語の資料(長文)が読める
・数学知識は高校卒業程度、大学の微分積分や線形代数・統計は良く分からない
この講義は機械学習全般について基礎的な所から学ぶ事が出来ます。他の教材に比べてより初学者に適していると思いました。
講義は全て英語です。もっとも、日本語の字幕が映像に付いているので問題なく理解する事が出来ます(細かい誤訳はあります)。ただし、提出を要求される確認テストとプログラミング課題の説明資料は全て英語です。精度向上の著しいGoogle翻訳に入力するとしても、誤訳を訂正する為の文法知識は必要だと思います。
講義では当然数式が出てきます。ですが、1つ1つの式についてしっかりとした説明をしてくれます。微分積分や線形代数についてよく知らないという方でも講義についていけるようになっています。逆に大学で線形代数と微分積分を学んだ方には、そうした説明が退屈に思えるかもしれません。そのような方にはより高度な教材の使用をオススメします。
プログラミングに関しては何らかの言語を少しでも使った経験があれば心配はありません。Octave/Matlabは他の言語に比べて学習コストが低いです。使ってみればすぐに慣れます。
具体的な講義の内容や「そもそもCourseraって何だよ」という点に関しては既に先達が記事を書かれていますので、そちらをご覧ください。
ざっくり纏めると学習した内容は以下になります。
・教師あり学習:回帰問題/分類問題(ロジスティック回帰、NN、SVM)
・教師なし学習:クラスタリング(K-means)/主成分分析/異常検知
・ビッグデータへの対応:確率的最急降下法/オンライン学習/Map-Reduce
・その他:未学習と過学習/交差検証/正規化/正則化/協調フィルタリング/天井分析
「講義内容に重要な手法が含まれていない」などの意見もありますが、個人的には講義の内容に満足しています。単に手法について学習するのではなく、「未学習や過学習」、「交差検証」などの基本的な考え方について学ぶ事が出来たのは貴重な体験でした。(他の本にも書いてありますが)
「テストデータを入れた結果を見て、ハイパーパラメータをチューニングする」がNGな理由などは重要だと思いました。
以下、動機や背景など個人的な話です。何かの参考になればどうぞ。
学習を始めた主な理由
・巷でAIと騒がれる物がどのようにして答えを導くのか単純に興味があった。
・趣味関係でフォローした方が機械学習をやっていて、仰っている事の意味を少しでも理解したいと思った。
・普段の業務が人とのコミュニケーションやエクセル/パワーポイントを主体としており、技術者志向(コミュ障理系修士卒)の自分には結構辛く、没頭できる逃避先を探していた。
学習前に持っていた知識
・数学:電磁気・電気電子回路を解く為の要素としてある程度理解。研究は太陽電池な為ほぼ忘れていた。
・プログラム:CとJava CはB2の頃数値解析のプログラムをゼロから作る課題を個人的に出されてた。弱い。
・英語:文章は何とか読める。音は呪文。話せない。
・統計:講義中は実験のレポート書いてた。研究では少しだけ使おうとした。(成果とは全く無関係)
分野に関する今後の学習予定など(仕事の合間に)
・Pythonのライブラリを使って色々試してみる。
・統計学を勉強する。統計検定2級は取得済みなのでまずは準1級を目標にしたい。
・前処理やデータの収集段階についても勉強したい。
ちらっとKaggleみてみましたが複数の機械学習の手法を組み合わせた複雑なモデル等があり、初めて飛行機を目の当たりにした時のような童心の驚きを感じました。今後も様々な分野の技術や専門性に対する敬意を大切にして参ります。
最後に
インターネットで検索すると初学者向けの教材が色々紹介されていて、何から始めようか迷うと思います。良い参考書や教科書を探すのは大事ですが、ある程度絞りを付けた後は、とにかくやってみるというのが重要なのだと良く言われます。私自身初心者ですし、人に説教できるほど偉くはありませんが、今後も「試しに何かをしてみる」という姿勢を大事にしていきたいと思います。